Pix4D Review
Overview: This lab will use Pix4D software to construct a orthomosaic image. Previously, this class had only made georeferenced mosaic imagery. The software Pix4D is the current premier software for constructing point clouds, and is also very easy to use.
Before starting Pix4d, it is important to make sure the images are highly overlapped to create a 3D model that is accurate. The more overlap between images, the more accurate the 3D model will be. More overlap leads to better automatic aerial triangulation which creates a sharper 3D model. If the user if flying over sand or snow the overlap must be at least 85% frontal overlap and at least 70% side overlap. A large percentage of overlap is needed because sand and snow have very little visual content, so each overlapping image can get as much contrast between images as possible. Rapid check is to verify the proper areas and coverage of the data collection. Rapid check processes the data very quickly, but the results have fairly low accuracy.
Pix4d can process multiple flights at once as long as the coordinate system (both horizontal and vertical) of the images is the same. Oblique images can be processed in Pix4d as long as they have good overlap and GCPs. GCPs are not necessary to use Pix4d, but they are highly recommended because they create a much more accurate model. The quality report is used to find the strength and quality of the matches.
Pix4D Software:
Dr. Hupy provided the class with UAV imagery from a sand mine south of Eau Claire in order to complete this lab. To start, all images are imported into Pix4d mapper. The area of interest (AOI) is chosen and the flight path can then be visualized. For this lab, a freely drawn polygon was used to create the AOI. After processing the images, the quality report is then created and provides specific details about the images. Figure 1 is the quality report for this lab.
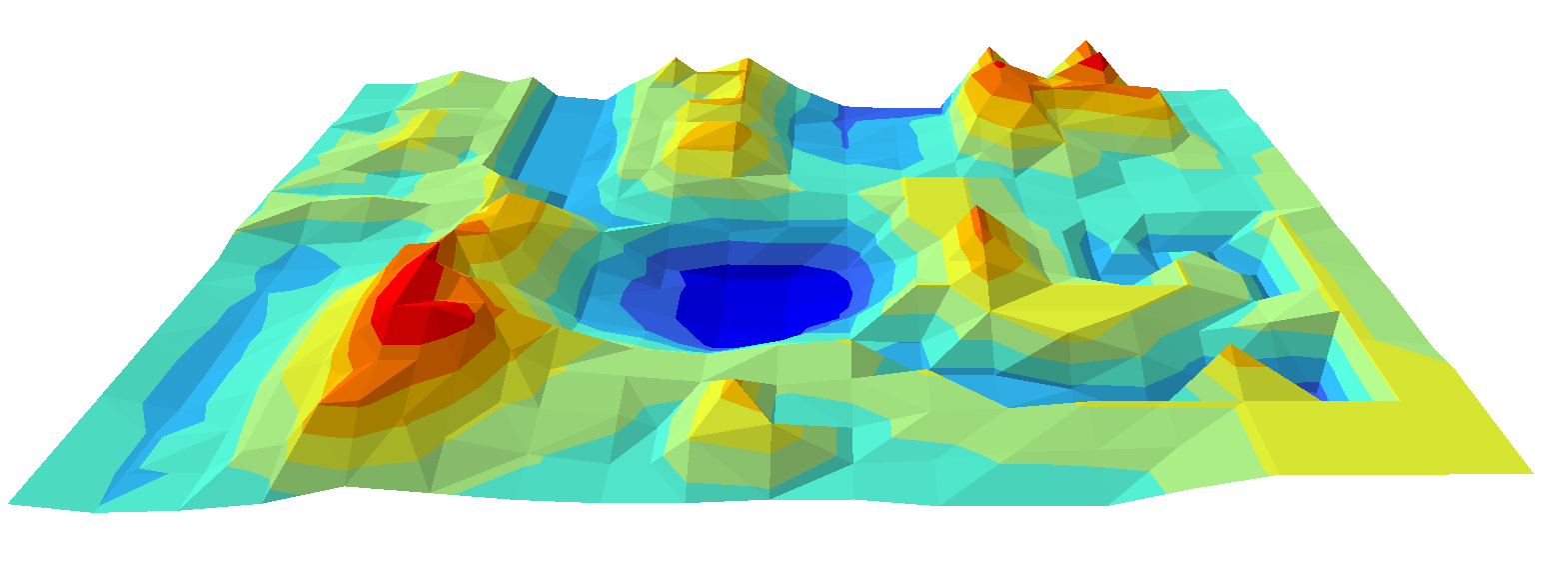
Image 2 is a orthomosaic and the corresponding sparse Digital Surface Model (DSM) before densification created in the report.
Dr. Hupy provided the class with UAV imagery from a sand mine south of Eau Claire in order to complete this lab. To start, all images are imported into Pix4d mapper. The area of interest (AOI) is chosen and the flight path can then be visualized. For this lab, a freely drawn polygon was used to create the AOI. After processing the images, the quality report is then created and provides specific details about the images. Figure 1 is the quality report for this lab.
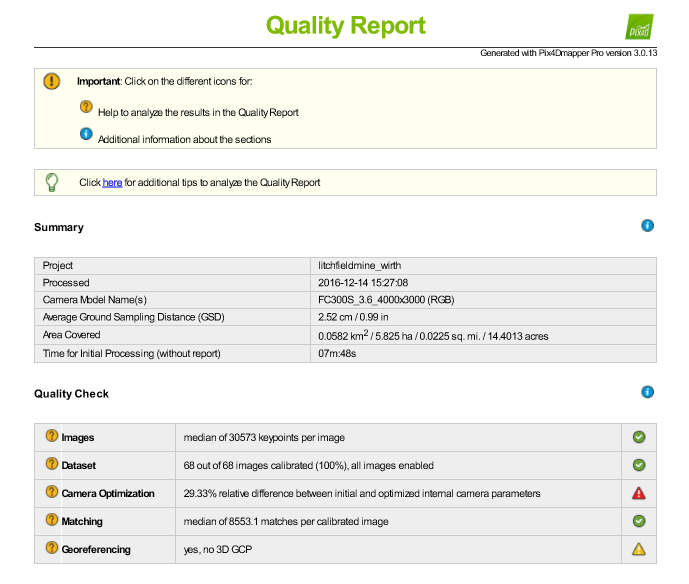 |
| Figure 1: Summary of the quality report |
Image 2 is a orthomosaic and the corresponding sparse Digital Surface Model (DSM) before densification created in the report.
 |
| Figure 2: Orthomosaic and DSM based off the report |
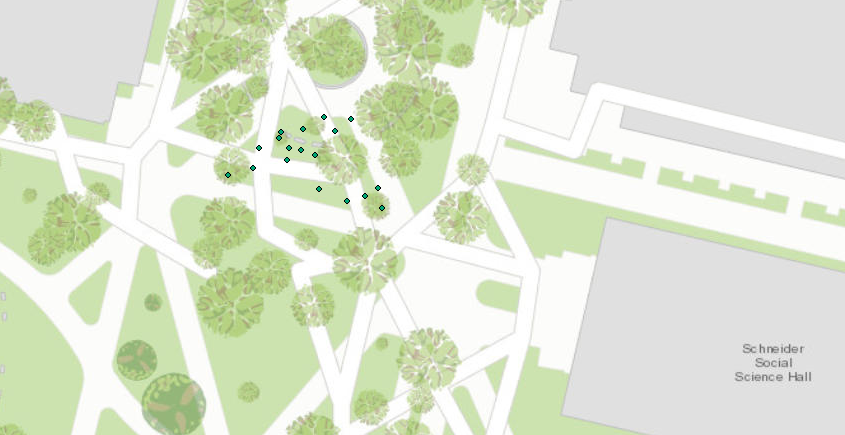
Figure 3 is an image produced by the quality report showing areas of overlap with the images. Areas in green are the areas that have multiple overlapping images. Areas that are red and yellow are areas where overlap is poor. Areas in the middle of the image have more overlap than the edges of the image. As long as the area of interest is an area of high overlap, the output will be of high quality.
 |
| Figure 3: The areas of overlap in the AOI |
Final Overview:
This lab introduced how to quickly and easily use pix4D to process UAV data. Pix4D is a great way to visualize 3D data and produce a high quality map. Pix4D can be used by anyone with UAV data to create a map. Overall, this was a great lab to complete to finish class.
This lab introduced how to quickly and easily use pix4D to process UAV data. Pix4D is a great way to visualize 3D data and produce a high quality map. Pix4D can be used by anyone with UAV data to create a map. Overall, this was a great lab to complete to finish class.